Powering the Future of Sustainable Transportation Introduction One of the biggest reasons behind Tesla's rapid growth is its network of Gigafactories. These massive manufacturing facilities are designed to produce electric vehicles (EVs), batteries, energy storage systems, and other clean-energy products at an unprecedented scale. By building Gigafactories around the world, Tesla has transformed the way vehicles and batteries are manufactured, helping accelerate the global transition to sustainable energy. What is a Gigafactory? A Gigafactory is a large-scale manufacturing facility built by Tesla, Inc. to produce batteries, electric vehicles, and energy products. The name "Gigafactory" comes from the word "gigawatt-hour," reflecting the enormous battery production capacity of these plants. Tesla's goal is to reduce manufacturing costs, increase production efficiency, and make electric vehicles more affordable for consumers worldwide. Major Tesla Gigafactorie...
Page Replacement
* In order to make almost all the use of virtual memory, we load several processes into memory at the same time. Since we only fill the pages that are actually required by each process at any given time, there is room to load many more processes than if we had to load in the entire process.
* However memory is also required for other purposes ( such as I/O buffering ), and what happens if some process suddenly decides it needs more pages and there aren't any free frames available? There are some feasible solutions to consider:
1. Modify the memory used by I/O buffering, etc., to free up some frames for user processes. The decision of how to allote memory for I/O versus user processes is a complex one, yielding different policies on different systems. (Some allote a fixed amount for I/O, and others let the I/O system fulfilled for memory along with everything else)
2. Place the process requesting extra pages into a wait queue until some free frames become available.
3. Interchange some process out of memory completely, freeing up its page frames.
4. Detect some page in memory that isn't being used right now, and swap that page
only out to disk, freeing up a frame that can be alloted to the process requesting it. This is called as page replacement, and is the most common solution. There
are many discrete algorithms for page replacement, which is the subject of the
remainder of this section.

Basic Page Replacement
* The previously discussed page fault processing believe that there would be free frames available on the free-frame list. Now the page-fault handling must be adjusted to free up a frame if required, as follows:
1. Detect the location of the desired page on the disk, either in interchange space or in the file system.
2. Find a free frame:
a) If there is a free frame, utilize it.
b) If there is no unoccupied frame, use a page-replacement algorithm to choose an
existing frame to be restored, known as the victim frame.
c) Write the victim frame to disk. Switch all associated page tables to specify that this page is no longer in memory.
3. Read in the wanted page and store it in the frame. Adjust all related page and
frame tables to indicate the change.
4. Resume the process that was waiting for this page.
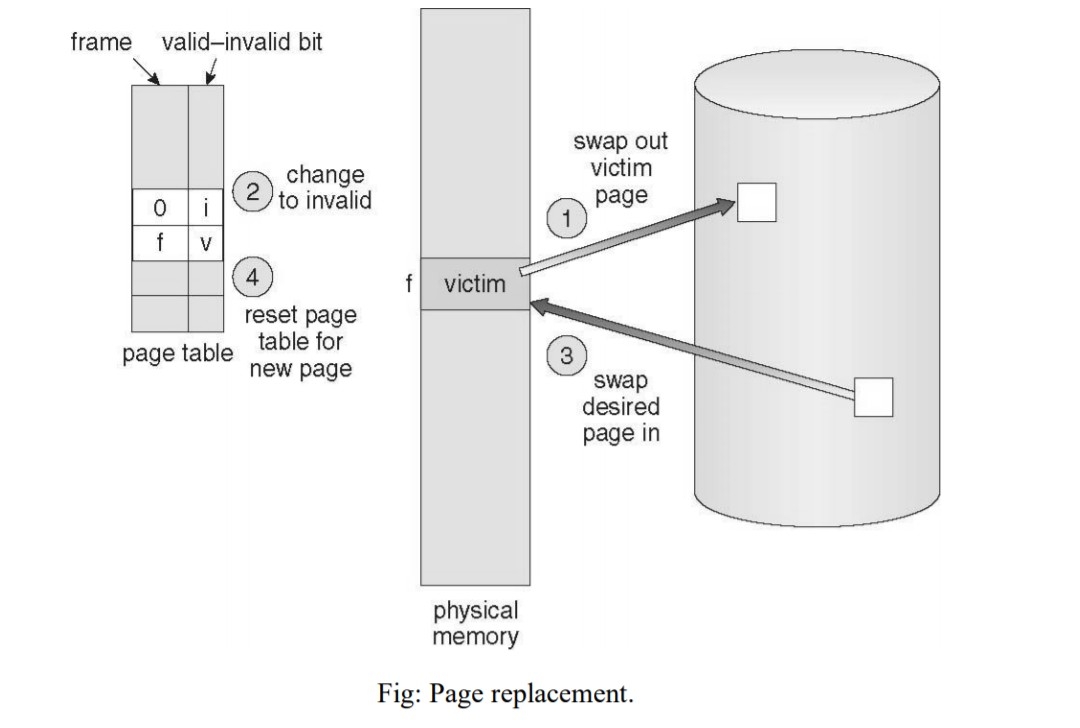
* Note that step 3c adds an extra disk write to the page-fault handling, successfully doubling the time required to process a page fault. This can be reduced somewhat by alloting a modify bit, or dirty bit to each page, signifying whether or not it has been changed since it was last loaded in from disk. If the dirty bit has not been set, then the page is not changed, and does not need to be written out to disk. Otherwise the page write is required. It should come as no surprise that many page replacement plans mainly
look for pages that do not have their dirty bit set, and preferentially choose clean pages as victim pages. It should also be obvious that not modifiable code pages never get their dirty bits set.
* There are two major requirements to execute a successful demand paging system. We must develop a frame allocation algorithm and a page replacement algorithm. The former centers around how many frames are allocated to every process (and to other needs), and the latter compact with how to choose a page for replacement when there are no free frames available.
* The overall goal in selecting and adjusting these algorithms is to make the lowest number of overall page faults. Because disk retrieve is so slow respective to memory access, even slight increments to these algorithms can yield large improvements in overall system performance.
* Algorithms are estimated using a given string of memory accesses known as a reference string, which can be generated in one of (at least) three common ways:
1. Randomly caused, either evenly distributed or with some distribution curve based on observed system behavior. This is the speedest and easiest way, but
may not consider real performance well, as it disregard locality of reference.
2. Specifically designed sequences. These are useful for demonstrating the properties of comparative algorithms in issued papers and textbooks, ( and also for homework and exam problems )
3. Recorded memory references from a live system. This may be the best method,but the amount of data collected can be huge,on the order of a million addresses per second. The volume of gathered data can be reduced by making two important observations:
i. Only the page number that was accessed is permenant. The offset within that page does not influence paging operations.
ii. Successive accesses within the same page can be used as a single page
request, because all requests after the first are pledged to be page hits. (Since there are no intercedeing requests for other pages that could delete this page from the page table)
Example: So for example, if pages were of size 100 bytes, then the order of address requests ( 0100, 0432, 0101, 0612, 0634, 0688, 0132, 0038, 0420 ) would reduce to page requests ( 1, 4, 1, 6, 1, 0, 4 )
* As the number of accessible frames increases, the number of page faults should decrease, as shown in below Figure:

FIFO Page Replacement
* A easy and plain page replacement method is FIFO, i.e. first-in-first-out.
* As new pages are entered in, they are added to the tail of a queue, and the page at the head of the queue is the next victim. In the following example, 20 page requests outcome in 15 page faults:

* Although FIFO is simple and easy, it is not always proper, or even well organized.
* An fascinating effect that can happen with FIFO is Belady's anomaly, in which expanding the number of frames available can actually increase the number of page faults that occur! Consider, for example, the following chart located on the page order (1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 ) and a varying number of accessible frames. Obviously the maximum number of condemns is 12 (every request generates a fault ), and the minimum number is 5 (each page loaded only once), but in between there are some interesting results:

Optimal Page Replacement
* The finding of Belady's anomaly guide to the look for an optimal page-replacement algorithm, which is simply that which yields the lowest of all possible page-faults, and which does not suffer from Belady's anomaly.
* Such an algorithm does subsist and is called OPT or MIN. This algorithm is easily "Replace the page that will not be used for the prolong time in the later."
* For example, the above fig shows that by requesting OPT to the same reference string used for the FIFO example, the minimum number of possible page faults is 9. Since 6 of the page-faults are inevitable ( the first reference to each new page ), FIFO can be shown to require 3 times as many (extra ) page faults as the optimal algorithm. ( Note: The book reveals that only the first three page faults are required by all algorithms, specifying that FIFO is only twice as bad as OPT)
* Unfortunately OPT cannot be executed in practice, because it requires foretelling the future, but it makes a nice benchmark for the comparison and evaluation of real proposed new algorithms.
* In practice most page-replacement algorithms try to roughly OPT by estimating in one fashion or another what page will not be used for the longest period of time. The basis of FIFO is the prediction that the page that was conduct in the longest time ago is the one that will not be needed again for the longest future time, but as we shall see, there are many other estimation methods, all striving to match the performance of OPT.

LRU Page Replacement
* The estimation behind LRU, the Least Recently Used, algorithm is that the page that has not been used in the prolong time is the one that will not be used again in the near future. (Note the contrast between FIFO and LRU: The previous looks at the previous load time, and the final looks at the oldest use time)
* Some view LRU as related to OPT, except looking backwards in time instead of forwards.(OPT has the interesting property that for any reference string S and its reverse R, OPT will create the same number of page faults for S and for R. It turns out that LRU has this same quality)
*Below figure demonstrates LRU for our sample string, submiting 12 page faults, ( as compared to 15 for FIFO and 9 for OPT)

* LRU is regarded a good replacement scheme, and is often used. The problem is how completely to execute it. There are two simple procedures frequently used:
1. Counters. Every memory access increments a counter, and the current value of this counter is kept in the page table entry for that page. Then detecting the LRU page has simple searching the table for the page with the smallest counter value. Note that spilled of the counter must be observed.
2. Stack. Another method is to use a stack, and whenever a page is obtained, pull that page from the central of the stack and place it on the top. The LRU page will
always be at the bottom of the stack. Because this needs deleting objects from the central of the stack, a doubly linked list is the recommended data structure.
* Note that both executions of LRU require hardware support, either for increasing the counter or for managing the stack, as these operations must be performed for every memory access.
* Neither LRU or OPT exhibit Belady's anomaly. Both belong to a group of page-
replacement algorithms known as stack algorithms, which can never reveal Belady's anomaly. A stack algorithm is one in which the pages hold in memory for a frame set of size N will always be a subset of the pages stay for a frame size of N + 1. In the case of LRU, ( and particularly the stack execution thereof ), the top N pages of the stack will be the same for all frame set sizes of N or anything larger.

LRU-Approximation Page Replacement
* Unfortunately full execution of LRU needs hardware support, and few systems givee the full hardware support compulsory.
* However many systems issue some degree of HW support, enough to estimate LRU fairly well. (In the truancy of ANY hardware support, FIFO shall be the best available choice)
* In particular, many systems give a reference bit for every entry in a page table, which is set anytime that page is obtained. Initially all bits are set to zero, and they can also all be freed at any time. One bit of precision is enough to distinguish pages that have been accessed since the last clear from those that have not, but does not provide any finer grain of detail.
Additional-Reference-Bits Algorithm
* Finer grain is possible by carrying the most recent 8 reference bits for each page in an 8-bit byte in the page table entry, which is interpreted as an unsigned int.
• At periodic intervals ( clock interrupts ), the OS removes over, and right-shifts each
of the reference bytes by one bit.
• The high-order ( leftmost ) bit is then pervade in with the current value of the
reference bit, and the reference bits are freed.
• At any given time, the page with the lowest value for the reference byte is the LRU page.
* Obviously the specific number of bits used and the frequency with which the reference byte is renovate are adjustable, and are tuned to give the fastest performance on a given hardware platform.
Second-Chance Algorithm
* The second chance algorithm is basically a FIFO, except the reference bit is used to give pages a second chance at staying in the page table.
• When a page must be restored, the page table is scanned in a FIFO ( circular
queue ) manner.
• If a page is establish with its reference bit not set, then that page is choosed as the next victim.
• If, however, the next page in the FIFO does own its reference bit set, then it is
given a second chance:
- The reference bit is freed, and the FIFO search continues.
- If some other page is found that did not own its reference bit set, then that
page will be selected as the victim, and this page ( the one being given the
second chance ) will be permited to stay in the page table.
- If , however, there are no other pages that do not own their reference bit
set, then this page will be selected as the victim when the FIFO search circles back around to this page on the second pass.
* If all reference bits in the table are set, then second chance devalues to FIFO, but also requires a complete search of the table for every page-replacement.
* As long as there are some pages whose reference bits are not set, then any page
referenced frequently enough acquires to stay in the page table indefinitely.
* This algorithm is also known as the clock algorithm, from the hands of the clock moving around the circular queue.

Enhanced Second-Chance Algorithm
* The enhanced second chance algorithm looks at the reference bit and the modify bit (dirty bit) as an ordered page, and categorizes pages into one of four classes:
1. ( 0, 0 ) - Neither recently used nor modified.
2. ( 0, 1 ) - Not recently used, but modified.
3. ( 1, 0 ) - Recently used, but clean.
4. ( 1, 1 ) - Recently used and modified.
* This algorithm finds the page table in a circular fashion ( in as many as four passes ), looking for the first page it can find in the lowest numbered category. I.e. it first makes a pass looking for a ( 0, 0 ), and then if it can't detect one, it makes another pass looking for a ( 0, 1 ), etc.
* The main difference between this algorithm and the preceding one is the liking for replacing clean pages if possible.
Counting-Based Page Replacement
* There are several algorithms based on including the number of references that have been made to a given page, such as:
• Least Frequently Used, LFU: Replace the page with the least reference count. A
problem can happen if a page is used frequently initially and then not used any
more, as the reference count remains high. A solution to this problem is to right-
transfer the counters periodically, yielding a time-decaying average reference count.
• Most Frequently Used, MFU: Replace the page with the highest reference count.
The logic behind this idea is that pages that have already been referenced a lot
have been in the system a long time, and we are probably done with them,
whereas pages referenced only a few times have only recently been loaded, and
we still need them.
* In general counting-based algorithms are not commonly used, as their implementation is expensive and they do not approximate OPT well.
Page-Buffering Algorithms
There are a number of page-buffering algorithms that can be used in conjunction with the afore-mentioned algorithms, to improve overall performance and sometimes make up for inherent weaknesses in the hardware and/or the underlying page-replacement algorithms:
* Maintain a certain minimum number of free frames at all times. When a page-fault occurs, go ahead and allocate one of the free frames from the free list first, to get the requesting process up and running again as quickly as possible, and then select a victim page to write to disk and free up a frame as a second step.
* Keep a list of modified pages, and when the I/O system is otherwise idle, have it write these pages out to disk, and then clear the modify bits, thereby increasing the chance of finding a "clean" page for the next potential victim.
* Keep a pool of free frames, but remember what page was in it before it was made free. Since the data in the page is not actually cleared out when the page is freed, it can be made an active page again without having to load in any new data from disk. This is useful when an algorithm mistakenly replaces a page that in fact is needed again soon.
Applications and Page Replacement
* Some applications ( most notably database programs ) understand their data accessing and caching needs better than the general-purpose OS, and should therefore be given reign to do their own memory management.
* Sometimes such programs are given a raw disk partition to work with, containing raw data blocks and no file system structure. It is then up to the application to use this disk partition as extended memory or for whatever other reasons it sees fit.